

LLM-augmented KG: Large Language Model (LLM) And Knowledge Graph (KG) Patterns (Part 2/3)
LLM-augmented KG


In this series of articles, we will explain Large Language Models, Knowledge Graphs and their combinations to examine the popular patterns of combining them and finally discuss to what extent this patterns will persist or perish in the future.
These articles are co-written by Anis Aknouche and Ole Olesen-Bagneux, the first one dives into LLMs, the second dives into KGs, and the third dives into their combination and viability of their future coexistence. All three articles contain tangible ways that are useful for enterprise data management and science.

This article is part of a series of 3 articles to explain LLM + KG patterns. In this part (2/3), we will talk about Knowledge Graphs (KGs) and how they can be augmented using Large Language Models (LLMs).
You can find the first article, where we talk about Large Language Models (LLMs) and how they can be enhanced using Knowledge Graphs (KGs) at KG-enhanced LLM
1. What is a Knowledge Graph (KG) ?
As introduced in [1], a Knowledge Graph (KG) is, simply defined as:
An interlinked set of facts that describe real-world entities, events, or things and their interrelations in a human- and machine-understandable format.
In essence, a knowledge graph provides structured yet flexible representation of information, allowing systems to reason over and infer knowledge from existing connections.
From another perspective, knowledge graphs can also be regarded as Semantic Networks, as described in [24]:
Unlike strict logic or rigid database schemas, semantic networks provide a flexible knowledge representation where any concept can be associated with any other concept through an appropriate semantic relation. This flexibility enables semantic networks to represent incredibly nuanced domains in an intuitive graphical form.
When represented purely in a human-readable form, such a conceptual structure is often referred to as an Ontology—a formalized “map“ of entities and their interrelations. Ontologies have existed since the earliest forms of knowledge organization, from ancient taxonomies to modern scientific classifications. In the digital era, graph databases now enable the computational realization of these ontological structures, providing a dynamic and scalable means to organize, query, and evolve complex knowledge systems.
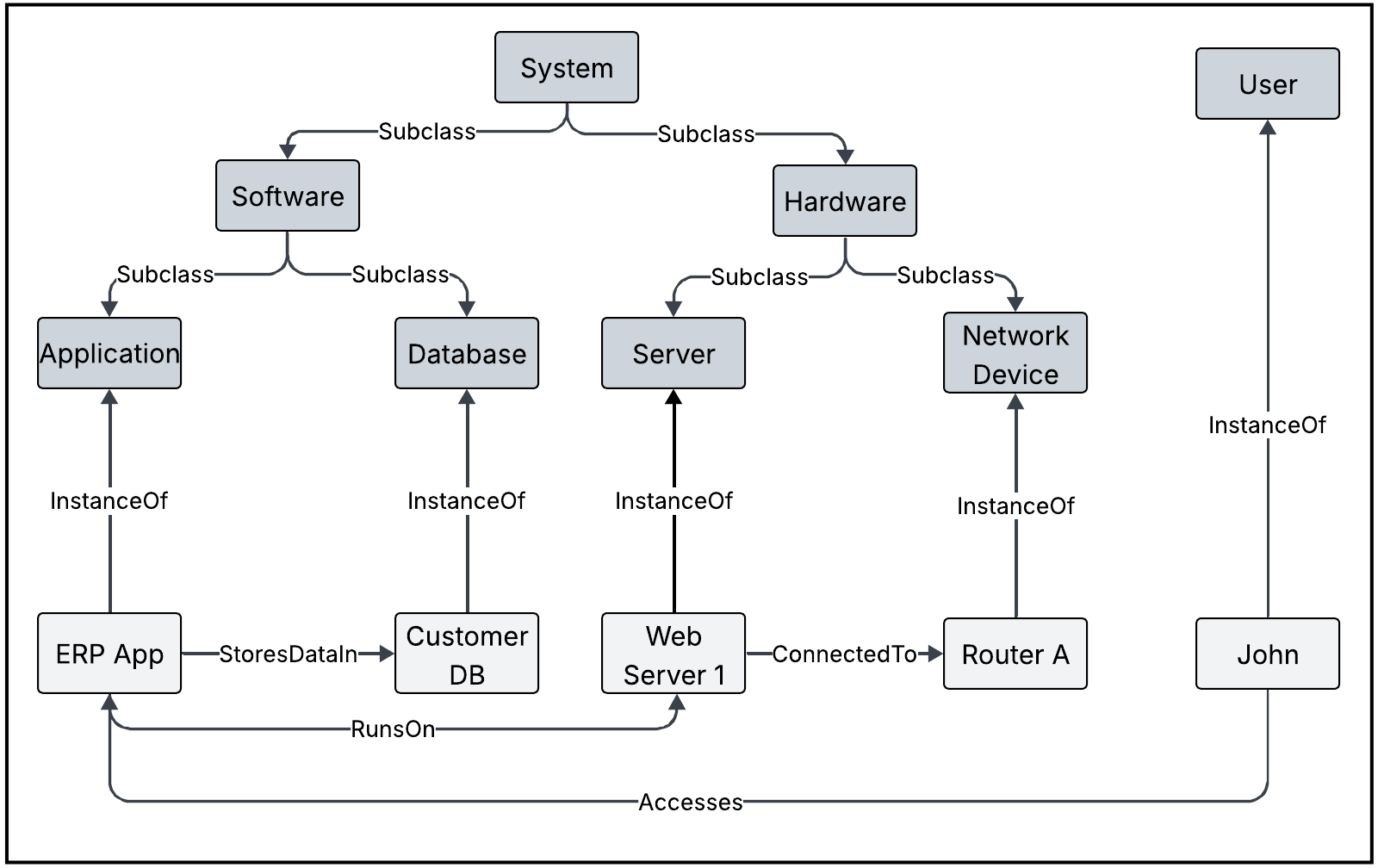
As summarized in [2], the term Knowledge Graph has been in circulation since the 1970s, but it gained momentum in the 2010s when major technology companies such as Google and Facebook restructured their core data infrastructures around graph-based models. This paradigm shift allowed for richer semantic search, improved contextual understanding, and greater connectivity across disparate data sources.
2. Knowledge Graph General Use Cases
With the rapid growth of AI solutions, Knowledge Graphs have been increasingly adopted across industry. They serve as central component in a variety of applications. The list is not exhaustive.
Knowledge Discovery and Reasoning. Uncovering new insights and inferring relationships that are not explicitly stored.
Data Integration and Interoperability. Unifying heterogeneous datasets and enriching entities with semantic information.
Question Answering (QA) and Search. Providing structured, context-aware answers.
Recommendation Systems. Supporting personalized and explainable suggestions based on entity relationships.
3. Knowledge Graph General Limitations
Knowledge Graphs offer significant advantages in managing knowledge, though a few potential drawbacks are worth discussing:
Limited Natural Language Understanding. Knowledge graphs are highly structured, making them easy for machine to process but often less intuitive for human readability.
Incompleteness. Knowledge graphs are frequently incomplete or inconsistently structured.
Resource-Intensive in Manual KG Construction. Building a Knowledge graphs from scratch is challenging and labor intensive, requiring significant human effort and domain knowledge.
Outdated Information. Knowledge graphs store facts that are accurate at the time of construction, but without regular updates, these facts can quickly become obsolete.
Metadata-Oriented. Knowledge graphs are highly effective at modeling relationships and metadata such as entity types, hierarchies, and ontologies. However, they are less suited for managing large volumes of raw, instance-level data, which restricts their usefulness in heavily data-driven applications.
4. LLM-augmented KG Explained
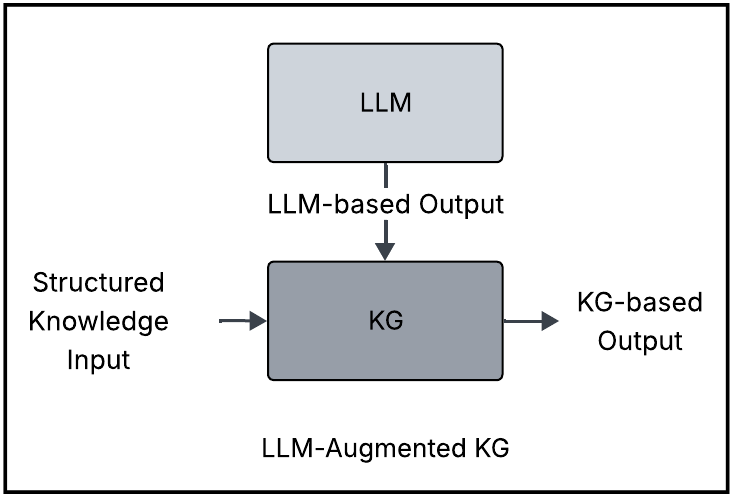
LLM-augmented Knowledge Graphs (KGs) [3] leverage the complementary strengths of Large Language Models (LLMs) and Knowledge Graphs. While KGs excel at representing structured information, they often suffer from incompleteness. This limitation can be mitigated by LLMs, which are adept at handling unstructured information.
As described in our previous article KG-enhanced LLM, LLMs learn explicit knowledge from their training text document corpus, and are able to infer implicit knowledge as well through a reasoning process [4]. This special ability towards unstructured information makes LLMs a great candidate to augment structured KGs.
LLMs can improve KGs in many ways.
Transform structured knowledge to natural language text
Infer new implicit and missing knowledge to face KG incompleteness
Construct KG from textual data
Answer to questions based on KG sub-graphs
5. LLM-augmented KG Approaches
As outlined in [3], numerous approaches exist for augmenting Knowledge Graphs with LLMs. In this section, we will focus these approaches: 1) LLM-augmented KG Embedding, 2) LLM-augmented KG Completion, 3) LLM-augmented KG Construction, 4) LLM-augmented KG-to-text generation, and 5) LLM-augmented KG Question Answering. The detail of each approach is presented below :
LLM-augmented KG Embedding. KG Embedding (KGE) encodes graph entities into embeddings that primarily capture structural information, while also incorporating semantic aspects. These embeddings support various downstream tasks such as Link Prediction or Clustering. LLM-augmented KGE can be implemented through different methods, including:
LLMs as Text Encoders. In this approach, an LLM is employed to encode a knowledge graph triple (h, r, t), where the head, relation, and tail entities are mapped into semantic embeddings, e_h, e_r and e_t, respectively. These initial embeddings are then fed to a KGE model, which produces the final embeddings, v_h, v_r, and v_t, respectively. As described in Pretrain-KGE [5], the training phase leverages a KGE loss function defined as
L = ( Y + f(v_h, v_r, v_t) - f(v_h’, v_r’, v_t’)) where f is the KGE scoring function, Y is a margin hyperparameter, and v_h’, v_r’, v_t’ are negative samples. This formulation enables the KGE model to learn structural information while retaining the semantic representation provided by the LLM encoder. Kepler [6], Nayyeri et al. [7], and CoDEx [8] are other approaches that integrate pre-trained language models with knowledge graphs.
LLMs for Joint Text and KG Embeddings. Another approach encodes knowledge graph triples (h, r, t) into textual sequences, where one entity is masked and the LLM is trained to predict the missing entity. For example, in kNN-KGE [9], entities and relations are represented by special tokens, and the graph triples are formatted as:
X = [CLS] h text_h [SEP] r [SEP] [MASK] text_t [SEP]
After training, the token representations produced by the LLMs serve as embeddings for entities and relations.
LLM-augmented KG Completion. Knowledge Graph Completion (KGC) is the task of inferring missing or implicit facts within a knowledge graph. Traditional KGC methods primarily rely on structural information, with little to no use of semantic context. In contrast, LLMs offer a promising direction, as they generate new facts grounded on the existing KG.
LLMs as Encoders. In this approach LLMs are used as encoders to encode KG facts represented in graph triples. Then, a model predicts the plausibility of a triple using a simple MLP or a conventional KG score function (eg., TransE [10], TransR [11]). We enumerate three different types of encoding:
Joint Encoding. The graph triple (h, r, t) is represented as a textual sequence [CLS] text_h [SEP] text_r [SEP] text_t [SEP] then the final hidden state of the [CLS] token is fed into a binary classifier to predict the possibility of the graph triple. KG-BERT [12] is an example.
MLM Encoding. Similar to the approach defined in (1.b), given a head h and relation r, a learning model can predict the tail entities t that are most likely to be linked to the head entity h through relation r. MEM-KGC [13] model uses Masked Entity Model (MEM) classification mechanism to predict the masked entities of the graph triple.
Separated Encoding. In this approach, we partition the triple (h, r, t) into two distinct partitions, i.e. (h, r) and t, which can be formatted as :
X_h_r = [CLS] text_h [SEP] text_r [SEP]
X_t = [CLS] text_t [SEP]
Then the two parts are encoded separately by an LLM, and we feed the final hidden states of the [CLS] tokens into a scoring function to predict the possibility of the graph triple. StAR [14], SimKGC [15] are examples.
LLMs as Generators. In this approach, LLMs are used as sequence-to-sequence generators. Having a graph triple defined as (h, r, t) for (head, relation, tail), the LLMs receive as input the textual representation of (h, r) as
[CLS] text_h [SEP] text_r [SEP] then the LLMs generate the corresponding tail entity (t) as [SEP] text_t [SEP]. As example, GenKGC [16] uses BART [17] as the backbone model with In-Context Learning (ICL) approach used in recent LLMs to predict the tail entity given the head and relation.
LLM-augmented KG Construction. Knowledge graph construction consists of creating graph structured representation of knowledge within a defined domain. If this raw and unstructured knowledge is in text format, then multiple stages are involved in order to construct the KG. The stages include 1) Entity discovery, 2) coreference resolution, and 3) relation extraction, as defined bellow:
Entity Discovery. It refers to the process of identifying and extracting named entities from unstructured data as text documents.
Named Entity Recognition (NER). A widely used approach for identifying and tagging named entities in textual data, such as people, organizations, locations, and other categories. Traditional models like Spacy [18], Stanza [19] and SparkNLP [20] remain state-of-the-art in this field. More recently approaches leveraging LLMs have emerged, achieving performance close to or matching current SOTA. For example, GenerativeNER [22] is a unified sequence-to-sequence (Seq2Seq) approach that formulates all NER subtasks—flat, nested, and discontinuous—as an entity span generation problem, enabling the use of pre-trained Seq2Seq models without specialized tagging schemes.
Entity Linking (EL). Also known as Entity Disambiguation, is the task of linking entities identified in text to their corresponding entries in a defined knowledge graph. ReFinED [21] introduces an efficient zero-shot-capable method that leverages fine-grained entity types and descriptions, processed through an LLM.
Coreference Resolution. An approach to identify all references of a given entity in a text. With CorefBERT [23], mentions of an entity are masked, and the model is trained to predict the masked mention’s corresponding referents. It uses both Mention Reference Prediction (MRP) task to select contextual candidates to recover the masked tokens, and Masked Language Modeling (MLM) to choose from vocabulary candidates.
Relation Extraction. An approach to extract relationships between defined entities in a given text. TRE [25], a Transformer for Relation Extraction, extending the OpenAI Generative Pre-trained Transformer [26]. Unlike previous relation extraction models, TRE uses pre-trained deep language representations instead of explicit linguistic features to inform the relation classification and combines it with the self-attentive Transformer architecture to effectively model long-range dependencies between entity mentions. HIN [27] use LLM to encode and aggregate entity representation at different levels, including entity, sentence, and document levels. SIRE [28] uses two LLM-based encoders to extract intra-sentence and inter-sentence relations.
End-to-End Knowledge Graph Construction. Researchers are exploring the use of LLMs for end-to-end KG construction. As an example, Grapher [30] from IBM Research, addresses the problem of Knowledge Graph (KG) construction from text, proposing a novel end-to-end multi-stage Grapher system, that separates the overall generation process into two stages. The graph nodes are generated first using pre-trained language model, followed by a simple edge construction head, enabling efficient KG extraction from the textual descriptions. For each stage they propose several architectural choices that can be used depending on the available training resources.
LLM-augmented KG-to-Text Generation. Since LLMs naturally excel at generating text, grounding them with knowledge graph facts can further improve the accuracy and quality of their outputs. In this approach we focus on how LLMs can leverage KGs to generate textual data based on graph knowledge representation. A good example is JointGT [31], that introduces a method for incorporating structure-preserving knowledge graph (KG) representations into Seq2Seq large language models. Given input sub-KGs alongside their corresponding text, it first encodes KG entities and relations as token sequences, which are then concatenated with textual tokens and fed into the LLM. After processing through the standard self-attention module, a pooling layer extracts contextual semantic representations of the KG entities and relations. These pooled representations are further integrated using a structure-aware self-attention layer. To strengthen the alignment between textual and graph information, JointGT also employs additional pre-training objectives, such as KG and text reconstruction from masked inputs.
LLM-augmented KG Question Answering. This approach builds on the idea of KG-to-text generation, but here the focus is on answering questions. The general framework involves using an LLM to extract entities and relations form the question, retrieving the related sub-graph, and employing another LLM to generate an answer based on the extracted data. A representative example is Nan et al. [33], which propose two LLM-based KGQA frameworks that adopt LLMs to identify entities and relations mentioned in the question, and then query the KG using these entity-relation pairs. In a more advance configuration, OREO-LM [32] combines large language models with knowledge graph (KG) reasoning. It introduces a Knowledge Interaction Layer (KIL) inside the transformer to let the LM interacts with a differentiable reasoning module that performs guided “random walks” over the KG. Starting from entities in the question, the model predicts relation paths, explores the KG, and aggregates the reached entity representations back into the LM. This integration allows the system to answer questions requiring multi-hop reasoning, improves accuracy in closed-book QA, and provides interpretable reasoning paths by showing which entities and relations were used to derive the answer.
6. Challenges of LLM-augmented KG
Integration Complexity. Bridging the gap between structured KG data and unstructured text-based models is non-trivial. LLMs work with sequences of tokens, while KGs operate on graph structures.
Scalability and Performance. Querying large-scale KGs during inference can be computationally expensive and slow.
Incomplete or Noisy Knowledge Graphs. KGs are often incomplete, domain-limited, or contain inaccuracies, which can lead to misleading outputs when used blindly.
Truthfulness in KG Construction using LLMs. Even with domain-specific LLMs, constructing knowledge graphs remains prone to errors or hallucinations. Ensuring verifiable and trustworthy knowledge often requires additional steps, such as human-in-the-loop review.
7. Conclusion
LLM-enhanced KGs have proven to be a foundational tool for organizing, representing, and reasoning over structured knowledge, enabling applications such as data integration, recommendation systems, question answering, and knowledge discovery. However, traditional KGs face limitations including incompleteness, high construction costs, outdated information, and challenges in handling raw or instance-level data. The integration of LLMs with KGs addresses many of these challenges by leveraging the LLMs ability to process unstructured data, infer implicit knowledge, generate natural language explanations, and guide multi-hop reasoning. LLM-augmented KG approaches—including KG embedding, completion, construction, KG-to-text generation, and KG-based question answering—demonstrate how structured and unstructured knowledge can be synergistically combined to produce more complete, interpretable, and flexible knowledge representations. Despite remaining challenges such as integration complexity, scalability, and truthfulness of automatically constructed KGs, LLM-augmented KGs represent a significant advancement in knowledge management and AI-driven reasoning.
8. Key Takeaways
LLM-augmented KG important advantages:
Synergy of Structured and Unstructured Knowledge
Generate Natural Language Text from Structured Graph Knowledge
Construction of KG from Textual Data
More Complete Knowledge Graphs
Reasoning within Knowledge Graphs
9. Reference
[1] J. Barrassa; J. Webber: Building Knowledge Graphs (O’Reilly, 2023)
[2] HOGAN, Aidan, BLOMQVIST, Eva, COCHEZ, Michael, et al. Knowledge graphs. ACM Computing Surveys (Csur), 2021, vol. 54, no 4, p. 1-37.
[3] PAN, Shirui, LUO, Linhao, WANG, Yufei, et al. Unifying large language models and knowledge graphs: A roadmap. IEEE Transactions on Knowledge and Data Engineering, 2024, vol. 36, no 7, p. 3580-3599.
[4] ZHANG, Yadong, MAO, Shaoguang, GE, Tao, et al. Llm as a mastermind: A survey of strategic reasoning with large language models. arXiv preprint arXiv:2404.01230, 2024.
[5] ZHANG, Zhiyuan, LIU, Xiaoqian, ZHANG, Yi, et al. Pretrain-KGE: Learning knowledge representation from pretrained language models. In : Findings of the association for computational linguistics: EMNLP 2020. 2020. p. 259-266.
[6] WANG, Xiaozhi, GAO, Tianyu, ZHU, Zhaocheng, et al. KEPLER: A unified model for knowledge embedding and pre-trained language representation. Transactions of the Association for Computational Linguistics, 2021, vol. 9, p. 176-194.
[7] NAYYERI, Mojtaba, WANG, Zihao, AKTER, Mst Mahfuja, et al. Integrating knowledge graph embeddings and pre-trained language models in hypercomplex spaces. In : International Semantic Web Conference. Cham : Springer Nature Switzerland, 2023. p. 388-407.
[8] ALAM, Mirza Mohtashim, RONY, Md Rashad Al Hasan, NAYYERI, Mojtaba, et al. Language model guided knowledge graph embeddings. IEEE Access, 2022, vol. 10, p. 76008-76020.
[9] WANG, Peng, XIE, Xin, WANG, Xiaohan, et al. Reasoning through memorization: Nearest neighbor knowledge graph embeddings. In : CCF International Conference on Natural Language Processing and Chinese Computing. Cham : Springer Nature Switzerland, 2023. p. 111-122.
[10] BORDES, Antoine, USUNIER, Nicolas, GARCIA-DURAN, Alberto, et al. Translating embeddings for modeling multi-relational data. Advances in neural information processing systems, 2013, vol. 26.
[11] LIN, Yankai, LIU, Zhiyuan, SUN, Maosong, et al. Learning entity and relation embeddings for knowledge graph completion. In : Proceedings of the AAAI conference on artificial intelligence. 2015.
[12] YAO, Liang, MAO, Chengsheng, et LUO, Yuan. KG-BERT: BERT for knowledge graph completion. arXiv preprint arXiv:1909.03193, 2019.
[13] CHOI, Bonggeun, JANG, Daesik, et KO, Youngjoong. Mem-kgc: Masked entity model for knowledge graph completion with pre-trained language model. IEEE Access, 2021, vol. 9, p. 132025-132032.
[14] WANG, Bo, SHEN, Tao, LONG, Guodong, et al. Structure-augmented text representation learning for efficient knowledge graph completion. In : Proceedings of the web conference 2021. 2021. p. 1737-1748.
[15] WANG, Liang, ZHAO, Wei, WEI, Zhuoyu, et al. Simkgc: Simple contrastive knowledge graph completion with pre-trained language models. arXiv preprint arXiv:2203.02167, 2022.
[16] XIE, Xin, ZHANG, Ningyu, LI, Zhoubo, et al. From discrimination to generation: Knowledge graph completion with generative transformer. In : Companion proceedings of the web conference 2022. 2022. p. 162-165.
[17] LEWIS, Mike, LIU, Yinhan, GOYAL, Naman, et al. BART: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. arXiv preprint arXiv:1910.13461, 2019.
[18] VASILIEV, Yuli. Natural language processing with Python and spaCy: A practical introduction. No Starch Press, 2020.
[19] QI, Peng, ZHANG, Yuhao, ZHANG, Yuhui, et al. Stanza: A Python natural language processing toolkit for many human languages. arXiv preprint arXiv:2003.07082, 2020.
[20] KOCAMAN, Veysel et TALBY, David. Spark NLP: natural language understanding at scale. Software Impacts, 2021, vol. 8, p. 100058.
[21] AYOOLA, Tom, TYAGI, Shubhi, FISHER, Joseph, et al. Refined: An efficient zero-shot-capable approach to end-to-end entity linking. arXiv preprint arXiv:2207.04108, 2022.
[22] YAN, Hang, GUI, Tao, DAI, Junqi, et al. A unified generative framework for various NER subtasks. arXiv preprint arXiv:2106.01223, 2021.
[23] YE, Deming, LIN, Yankai, DU, Jiaju, et al. Coreferential reasoning learning for language representation. arXiv preprint arXiv:2004.06870, 2020.
[24] Matthew R. Scott, Dr. Alex Acero. Building Agentic AI Systems. O’Reilly, Packt Publishing ,2025
[25] ALT, Christoph, HÜBNER, Marc, et HENNIG, Leonhard. Improving relation extraction by pre-trained language representations. arXiv preprint arXiv:1906.03088, 2019.
[26] RADFORD, Alec, NARASIMHAN, Karthik, SALIMANS, Tim, et al. Improving language understanding by generative pre-training. 2018.
[27] TANG, Hengzhu, CAO, Yanan, ZHANG, Zhenyu, et al. Hin: Hierarchical inference network for document-level relation extraction. In : Pacific-Asia conference on knowledge discovery and data mining. Cham : Springer International Publishing, 2020. p. 197-209.
[28] ZENG, Shuang, WU, Yuting, et CHANG, Baobao. SIRE: Separate intra-and inter-sentential reasoning for document-level relation extraction. arXiv preprint arXiv:2106.01709, 2021.
[30] MELNYK, Igor, DOGNIN, Pierre, et DAS, Payel. Grapher: Multi-stage knowledge graph construction using pretrained language models. In : NeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications. 2021.
[31] KE, Pei, JI, Haozhe, RAN, Yu, et al. Jointgt: Graph-text joint representation learning for text generation from knowledge graphs. arXiv preprint arXiv:2106.10502, 2021.
[32] HU, Ziniu, XU, Yichong, YU, Wenhao, et al. Empowering language models with knowledge graph reasoning for question answering. arXiv preprint arXiv:2211.08380, 2022.
[33] HU, Nan, WU, Yike, QI, Guilin, et al. An empirical study of pre-trained language models in simple knowledge graph question answering. World Wide Web, 2023, vol. 26, no 5, p. 2855-2886.
Thank you. Very technical. Most is above my understanding. Thus, Sections 6-7 very helpful for business considerations.